p. 115: The first code fragment is bad. It should read as follows:
int offset = 0;
while (true){
int bytesRead = in.read(data, offset, data.length - offset);
offset += bytesRead;
if (bytesRead == -1 || offset >= data.length) break;
}
p. 126: UTF-8 is a specified, byte-by-byte format that has no concept of endianness. Proper UTF-8 (which the data stream classes' UTF-8 isn't, see p. 116 and p. 400) are the same on big and little endian platforms. The UTF string written by DataOutputStream should be identical to the UTF string written by LittleEndianOutputStream. Consequently the
the writeUTF() method of LittleEndianOutputStream class in the book is incorrect (even more incorrect than Java's usual
incorrect UTF-8). Here's a corrected version:
/**
* Writes a string of no more than 65,535 characters
* to the underlying output stream using UTF-8
* encoding. This method first writes a two byte short
* in big endian order as required by the
* UTF-8 specification. This gives the number of bytes in the
* UTF-8 encoded version of the string, not the number of characters
* in the string. Next each character of the string is written
* using the UTF-8 encoding for the character.
*
* @param s the string to be written.
* @exception UTFDataFormatException if the string is longer than
* 65,535 characters.
* @exception IOException if the underlying stream throws an IOException.
*/
public void writeUTF(String s) throws IOException {
int numchars = s.length();
int numbytes = 0;
for (int i = 0 ; i < numchars ; i++) {
int c = s.charAt(i);
if ((c >= 0x0001) && (c <= 0x007F)) numbytes++;
else if (c > 0x07FF) numbytes += 3;
else numbytes += 2;
}
if (numbytes > 65535) throw new UTFDataFormatException();
out.write((numbytes >>> 8) & 0xFF);
out.write(numbytes & 0xFF);
for (int i = 0 ; i < numchars ; i++) {
int c = s.charAt(i);
if ((c >= 0x0001) && (c <= 0x007F)) {
out.write(c);
}
else if (c > 0x07FF) {
out.write(0xE0 | ((c >> 12) & 0x0F));
out.write(0x80 | ((c >> 6) & 0x3F));
out.write(0x80 | (c & 0x3F));
written += 2;
}
else {
out.write(0xC0 | ((c >> 6) & 0x1F));
out.write(0x80 | (c & 0x3F));
written += 1;
}
}
written += numchars + 2;
}
Double.longBitsToDouble() should be Double.doubleToLongBits()
p. 130, Example 7-9: The LittleEndianInputStream code is correct as stands. However it does more work than it needs to. It is only necessary
to check the last byte read to see if it's -1 in order to detect end of stream. If you read eight bytes, and the first is -1, then the next 7 are too.
The examples page has an updated version.
Another problem with this method is that
the various bytes are incorrectly shifted.
The algorithm for converting little-endian to big-endian
fails when any byte has its high order bit set, because the implicit conversion
to int when using the << operator throws in a sign bit.
Here's a correct variation of the readInt() method.
public int readInt() throws IOException {
int byte1, byte2, byte3, byte4;
synchronized (this) {
byte1 = in.read();
byte2 = in.read();
byte3 = in.read();
byte4 = in.read();
}
if (byte4 == -1) {
throw new EOFException();
}
return (byte4 << 24)
+ ((byte3 << 24) >>> 8)
+ ((byte2 << 24) >>> 16)
+ ((byte1 << 24) >>> 24);
}
p. 133:
UTF-8 is a specified, byte-by-byte format that has no concept of endianness. Proper UTF-8 (which the data stream classes' UTF-8 isn't, see p. 116 and p. 400) are the same on big and little endian platforms. The UTF string written by DataOutputStream should be readable by LittleEndianInputStream's readUTF() method. Consequently the
the readUTF() method of LittleEndianInputStream class in the book is incorrect. Here's a corrected version:
/**
* Reads a string of no more than 65,535 characters
* from the underlying input stream using UTF-8
* encoding. This method first reads a two byte short
* in big endian order as required by the
* UTF-8 specification. This gives the number of bytes in
* the UTF-8 encoded version of the string.
* Next this many bytes are read and decoded as UTF-8
* encoded characters.
*
* @return the decoded string
* @exception UTFDataFormatException if the string cannot be decoded
* @exception IOException if the underlying stream throws an IOException.
*/
public String readUTF() throws IOException {
int byte1 = in.read();
int byte2 = in.read();
if (byte2 == -1) throw new EOFException();
int numbytes = (byte1 << 8) + byte2;
char result[] = new char[numbytes];
int numread = 0;
int numchars = 0;
while (numread < numbytes) {
int c1 = readUnsignedByte();
int c2, c3;
// look at the first four bits of c1 to determine how many
// bytes in this char
int test = c1 >> 4;
if (test < 8) { // one byte
numread++;
result[numchars++] = (char) c1;
}
else if (test == 12 || test == 13) { // two bytes
numread += 2;
if (numread > numbytes) throw new UTFDataFormatException();
c2 = readUnsignedByte();
if ((c2 & 0xC0) != 0x80) throw new UTFDataFormatException();
result[numchars++] = (char) (((c1 & 0x1F) << 6) | (c2 & 0x3F));
}
else if (test == 14) { // three bytes
numread += 3;
if (numread > numbytes) throw new UTFDataFormatException();
c2 = readUnsignedByte();
c3 = readUnsignedByte();
if (((c2 & 0xC0) != 0x80) || ((c3 & 0xC0) != 0x80)) {
throw new UTFDataFormatException();
}
result[numchars++] = (char)
(((c1 & 0x0F) << 12) | ((c2 & 0x3F) << 6) | (c3 & 0x3F));
}
else { // malformed
throw new UTFDataFormatException();
}
} // end while
return new String(result, 0, numchars);
}
However, this would only prevent another thread from reading fromp. 137: In the first paragraph, "inif the second thread also synchronized onin. In general you can't count on this, so it's not really a solution.
DumpFilter from Chapter 4"
should read "DumpFilter from Chapter 6"
p. 137: In Example 7-10:
"Usage: java FileDumper2 [-ahdsilfx] [-little] file1 file2...");
"Usage: java FileDumper3 [-ahdsilfx] [-little] file1 file2...");
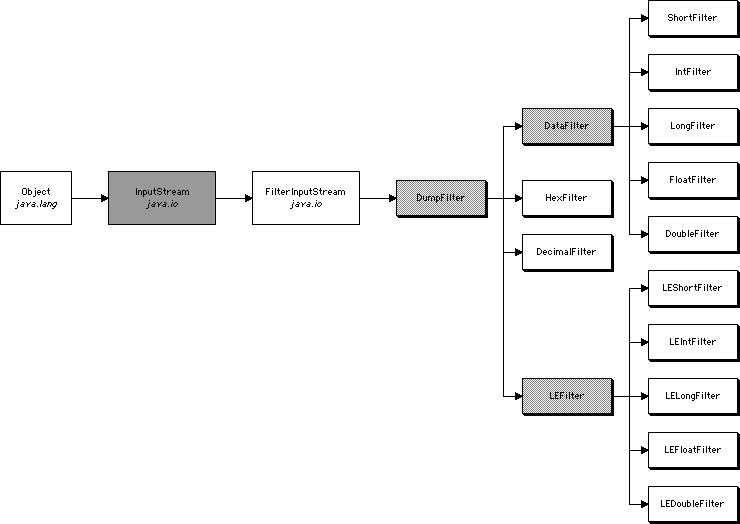
LEShortFilter should be a subclass of LEFilter, not DataFilter. This is the correct picture