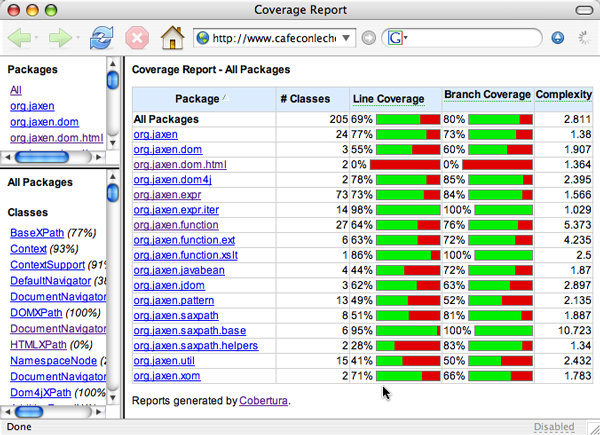
Code contributed without any tests:
Goal of package was to allow XPath to be used on regular HTML.
No matter what I did I could not make a test case hit this code.
Purpose was to convert "the element, but not attribute, names of an HTML document to upper or lower case, depending on your specification, so that lower case [element] xpath expressions will work just as well on HTML as they do on XHTML (which is case sensitive and enforces lower case on elements and attributes)."
In other words, the goal is that we can now write //p and have that same expression select all the paragraph elements in both HTML and XHTML documents.
BUT THIS DOESN'T WORK!
//p never selects paragraph elements in an XHTML document. In XHTML documents, unlike HTML documents, the p element is in a namespace. Thus, when querying an XHTML document you have to write //foo:p, where the foo prefix is bound to the XHTML namespace URI. (Remember, in XPath expressions we never use a default namespace not bound to a prefix, even if the instance documents do.)
Allowing the lower case name "p" in an XPath expression to match both p and P is insufficient to allow the same XPath expression to query both HTML and XHTML documents. You still need two different XPath expressions.
If you want to query an XHTML DOM, the regular, normal Jaxen DOM navigator works just fine, because XHTML is XML. And if you want to query an HTML DOM, then the regular, normal Jaxen DOM navigator also works just fine, because DOM HTML is still a well-defined tree that follows all the DOM rules. In this tree the element names happen to be upper case. But that's OK. It's in no way a problem for Jaxen or XPath.
Test first development would have prevented this package from ever hitting the CVS tree. Test-second development at least succeeded in eliminating it.